Core / RAG Workflow Engine
This section dives into the engine of the stack—the part that powers your Retrieval-Augmented Generation (RAG) solutions with just a YAML configuration file.
Core Workflow
The diagram below illustrates how the Core workflow processes user queries and documents step by step:
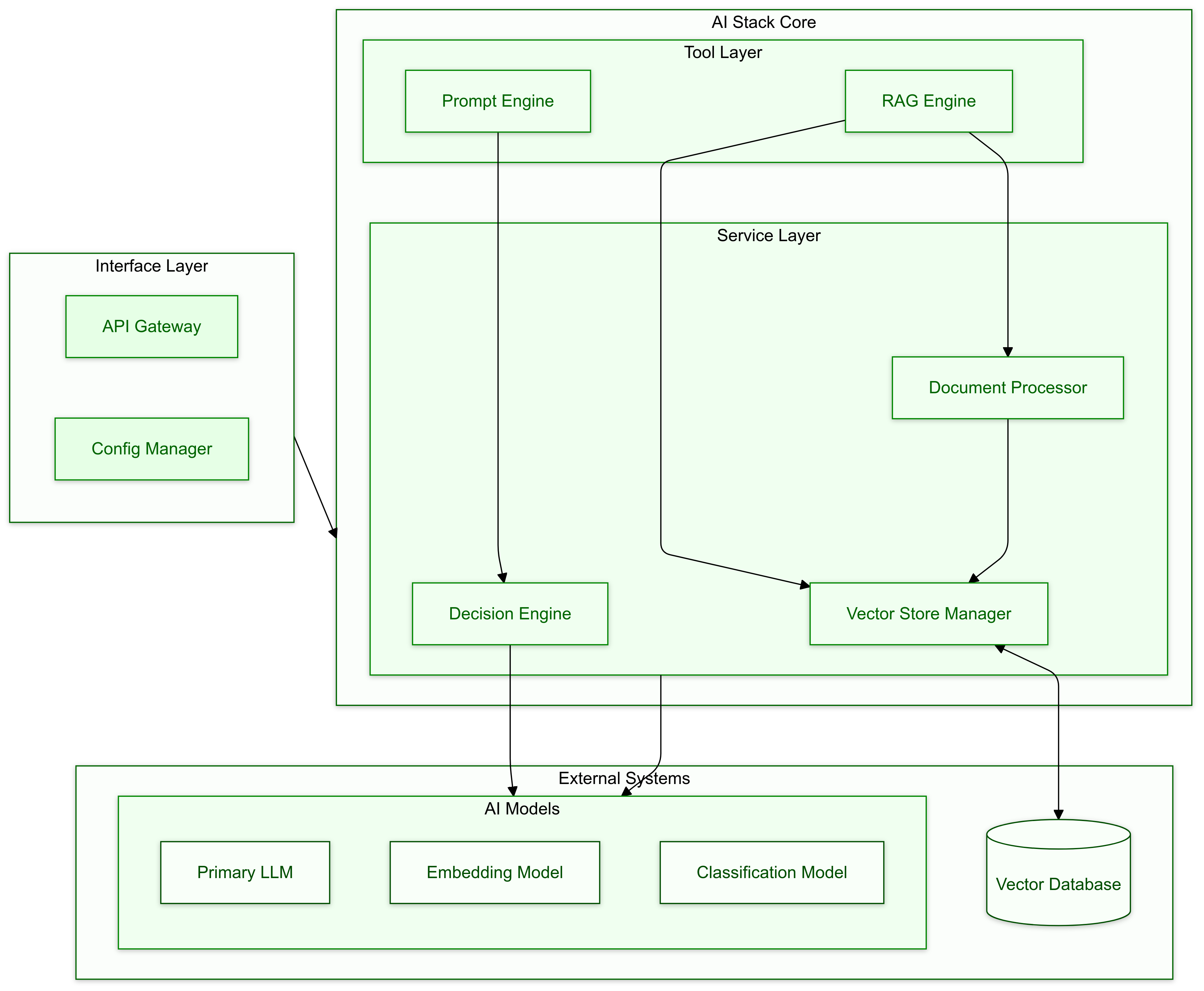
Here’s what happens under the hood:
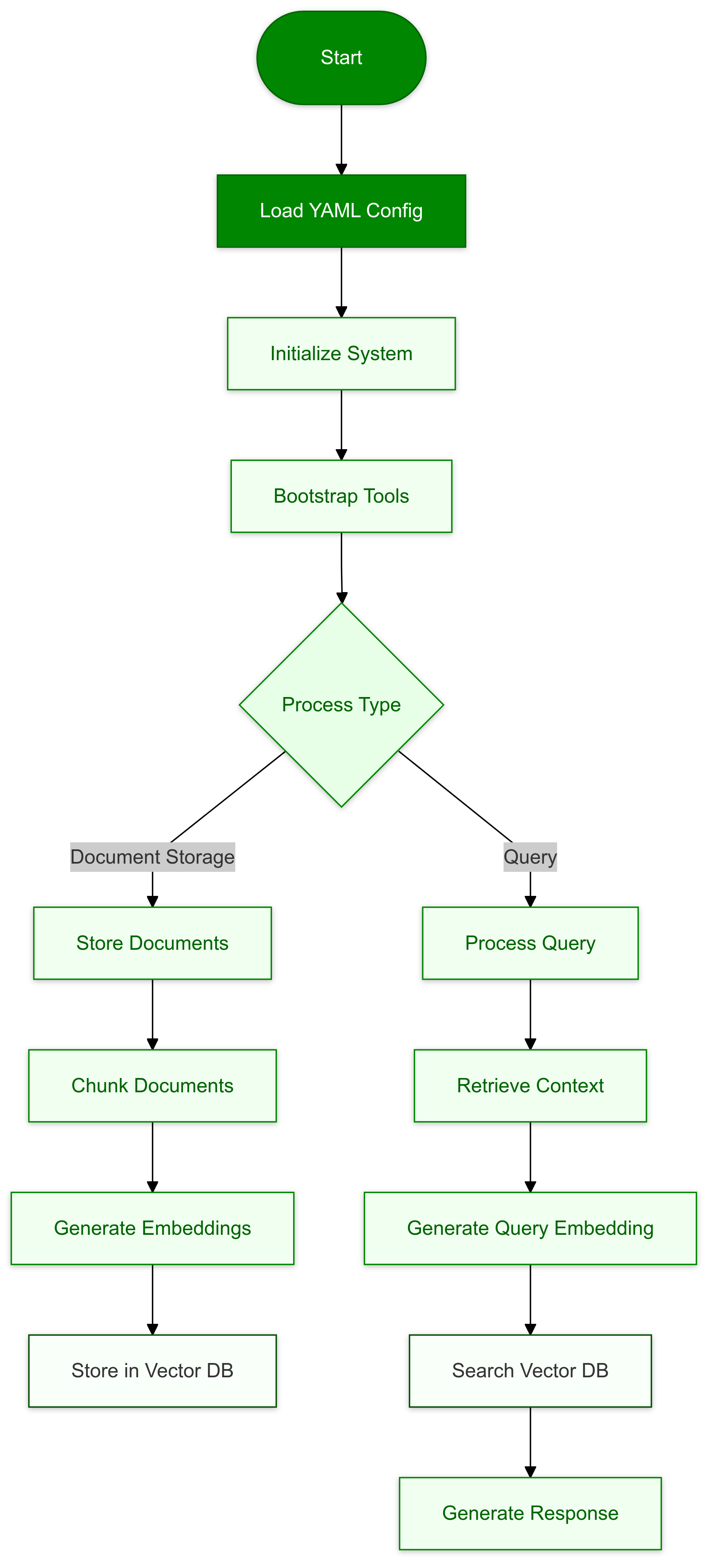
Step 1: Init
The process begins by loading your YAML configuration.
Step 2: Parse YAML Config
The configuration file is parsed, serving as the blueprint for the entire workflow.
Step 3: Initialize Tools
All the tools defined in the configuration are loaded and prepared for action.
Step 4: Create or Retrieve Collections
If working with a vector database, the system creates a new collection or retrieves an existing one for efficient data handling.
Step 5: Process and Store Documents
Documents are processed, chunked, and stored in the vector database within the appropriate collection. Each RAG tool manages its own dedicated collection.
Step 6: Classify and Select Tools (Documents)
Incoming documents are classified, and the right tool is selected for processing and storing the partitioned data chunks.
Step 7: Handle User Queries
The AI agent interacts with users, leveraging tools and the database to provide insights and responses.
Step 8: Classify and Select Tools (Queries)
Incoming queries are classified, and the most suitable tool is chosen. For RAG tools, this may involve retrieving stored documents. For prompt tools, a direct answer is generated.
Step 9: Retrieve Relevant Chunks
When required, relevant data chunks are fetched from the vector database to enhance responses.